PEGASUS:Pre-training with Extracted Gap-sentences for Abstractive Summarization
Abstract
추상적 요약(Abstractive Summarization)에 맞는 사전학습 모델인 PEGASUS를 제안한다. PEGASUS 모델은 트랜스포머(Transformer) 기반의 인코더-디코더 구조이고, 사전 학습을 위한 새로운 기법인 GSG도 함께 제안한다.
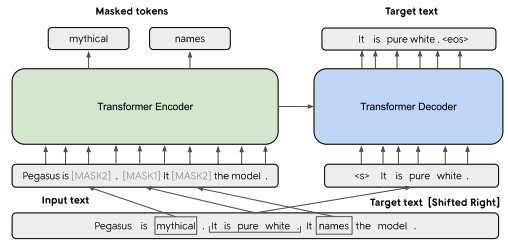
기본 구조는 표준 트랜스포머 인코더-디코더 구조이다. 위의 그림에서는 문장 1개는 [MASK1]로 마스킹 되어 Target 텍스트 생성에 사용하고, 다른 두 문장에서 랜덤 한 토큰을 [MASK2]로 마스킹 한다.
Introduction
추상적 요약이란?
기존 문장에서 요약문을 뽑아내는 것이 아닌, 요약 내용을 담은 새로운 문장을 생성하는 것
이 논문에서는 아래와 같은 내용을 소개할 예정이다.
-
추상적 요약을 위한 새로운 self-supervised 사전학습 모델과 Gap-Sentences Generation(GSG)를 제안하고, 문장을 선택하는 전략을 연구한다.
-
제안된 사전학습 모델이 넓은 범위의 Downstream에서도 좋은 성능을 내는지 평가한다.
-
fine-tuning 한 PEGASUS 모델이 label이 없는 큰 도메인에서 어떻게 좋은 성능을 달성하는지 소개한다.
-
모델을 검증하고, 인간 수준의 요약 성능을 보여주기 위해 사람 평가 연구를 진행한다. (XSum, CNN/DailyMail, Reddit TIFU 데이터 셋에서)
Pre-training Objectives
(비교를 위해 BERT의 masked-language model 방식을 함께 살펴보았다.)
Gap Sentences Generation (GSG)
- 추상적 요약을 위해 제안된 새로운 방식의 self-supervised pre-training objective
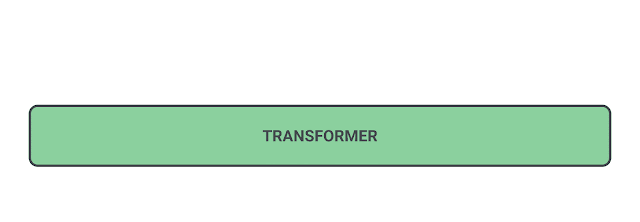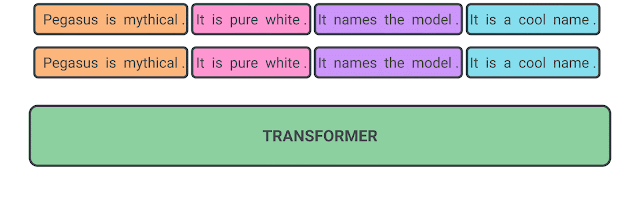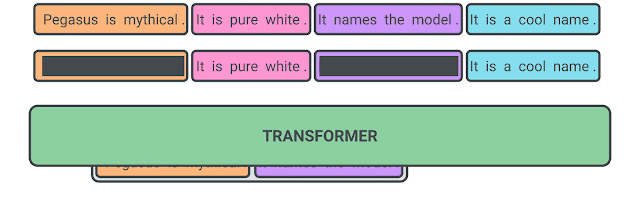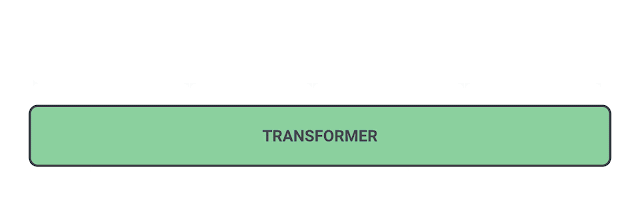
- GSR(Gap Sentences Ratio)에 따라 문장을 선택하고 마스킹
- 선택된 문장을 연결하여 pseudo-요약문으로 만듦.
- 선택된 문장 위치에 [MASK1]토큰을 넣은 후 모델에 넣는다.
- [MASK1] 토큰을 예측하는 방식으로 학습한다.
GSR이란?
문서 내 전체 문장 개수 대비 선택된 문장의 개수 비율
문장을 선택하는 전략
논문에서는 문장을 선택하는 전략을 세 가지 소개하고 있다.
- Random : 랜덤하게 m 개의 문장을 선택한다.
- Lead : 처음 m 개의 문장을 선택한다.
- Principal : 중요도에 따른 상위 m 개의 문장을 선택한다. 이때 중요도는 문장과 나머지 문서 사이의 ROUGE1-F1을 계산해서 사용한다.
- 옵션1: Ind or Seq -> 문장을 순서와 관계없이 선택 또는 연속적으로 선택
- 옵션2: Uniq or Orig -> n-gram을 집합으로 취급 또는 중복을 허용

Masked Language Model (MLM)
입력 텍스트에서 15% 토큰을 랜덤하게 선택한다. 이 토큰은 다음 3가지 과정 중 한 가지를 거치면서 마스킹 된다.
- 80% 확률로 [MASK2] 토큰으로 대체된다.
- 10% 확률로 임의의 토큰으로 대체된다.
- 10% 확률로 그대로 유지된다.
이것에 대한 자세한 내용은 BERT 논문에 나와있다.
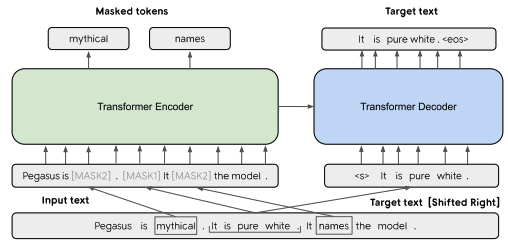
위의 구조에서는 GSG와 MLM을 동시에 적용하였지만, MLM이 Downstream Task의 성능을 개선하지 못했고, 이 논문의 최종 모델인 PEGASUS-Large에 적용하지 않았다.
Pre-training Corpus
- C4
- HugeNews
Downstream Tasks/Datasets
- XSum, CNN/DailyMail, NEWSROOM, Multi-News, Gigaword, WikiHow, Reddit TIFU, BIGPATENT, arXiv, PubMed, AESLC, BillSum
- 총 12개 사용했다.
Experiments
| Encoder, Decoder Layer 개수 | Hidden Size | Feed-Forward Layer 개수 | Self-Attention Head 개수 | Batch Size | 파라미터 수 | |
|---|---|---|---|---|---|---|
| PEGASUS-Base | 12 | 768 | 3072 | 12 | 256 | 223M |
| PEGASUS-Large | 16 | 1024 | 4096 | 16 | 8192 | 568M |
- Optimizer: Adafactor
- Dropout rate: 0.1
Adafactor이란?
메모리 사용량을 줄일 수 있는 Adam기반의 Optimizer
효율적인 실험을 위해 우선 4개의 데이터 셋을 이용해 실험을 진행했다.
- XSum
- CNN/DailyMail
- WikiHow
- Reddit TIFU
PEGASUS-BASE
시간과 자원을 절약하기 위해 사이즈를 줄인 PEGASUS-Base를 이용해 평가했다. 평가항목으로는 다음 세가지이다.
- Pre-training Corpus
- Pre-training Objectives
- 단어장 사이즈
Pre-training Corpus
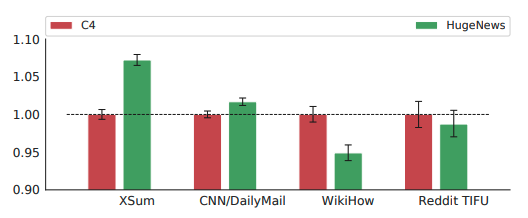
- 뉴스가 아닌 데이터셋 : C4가 효율적
- 뉴스 DownStream 데이터셋 : HugeNews가 효율적
Pre-training Objectives
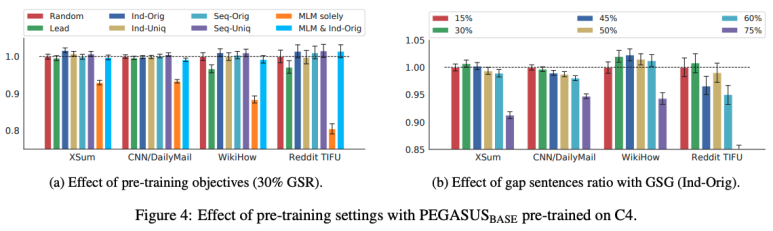
Effect of pre-training objectives
- 30%의 GSR에서 실험
- GSG : Ind-Orig > Seq-Uniq 순으로 성능이 좋음
- MLM : 단독으로 사용했을 경우 성능이 더 낮았고, GSG와 혼합한 방식도 GSG의 Random 방식과 비슷한 성능을 보임
Effect of gap sentences ratio with GSG (Ind-Orig)
Ind-Orig방식에서 실험- 공평한 실험을 위해 데이터셋을 최대 400단어를 갖도록 자름
- 50%이하일 때 대체적으로 좋은 성능을 보임
- CNN/DailyMail : 15%일때 성능이 좋음
- XSum,Reddit TIFU : 30%일때 성능이 좋음
- WikiHow : 45%일때 성능이 좋음
단어장 사이즈
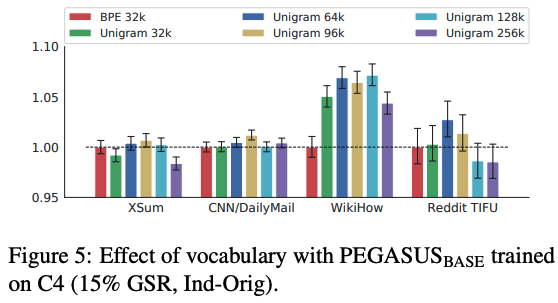
- 두가지 토크나이저를 사용 (Byte-pair-encoding = BPE, SentencePiece Unigram = Unigram)
- XSum, CNN/DailyMail : Unigram 96k일때 성능이 좋음
- WikiHow : Unigram 128k일때 성능이 좋음
- Reddit TIFU : Unigram 96k일때 성능이 좋음
PEGASUS-Large
PEGASUS-Base 실험 결과 적용된 것은 다음과 같다.
- Pre-training 방식 : GSG(Ind-Orig)
- GSR : 45% (30%와 비슷한 성능을 내기 위해 선택)
- 단어장 사이즈 : Unigram 96k
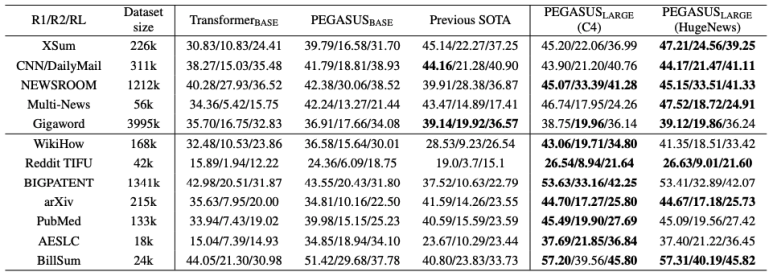
- PEGASUS-Base도 대부분의 Downstream에서 현재 SOTA에 비해 좋은 성능을 내고 있지만, PEGASUS-Large의 경우 모든 Downstream에서 SOTA보다 좋은 성능을 내고 있음
- 대부분 Downstream은 HugeNews로 사전학습한 모델이 더 높은 성능을 보임
- 단, WikiHow의 경우 C4로 사전학습한 모델이 더 높은 성능을 보임
Zero and Low-Resource Summarization
현실에서는 대용량의 요약 지도학습 데이터를 모으기가 쉽지 않다. 때문에 이 논문에서는 사전학습을 시킨 모델이 적은 데이터에서도 좋은 성능을 내는지 실험했다.
PEGASUS-Large모델을 fine-tuning 하기 위한 설정은 다음과 같다.
| step | 배치 사이즈 | learning rate |
|---|---|---|
| 2000 | 256 | 0.0005 |
Trainsformer-base model은 Full supervised dataset으로 fine-tuning이 됨.
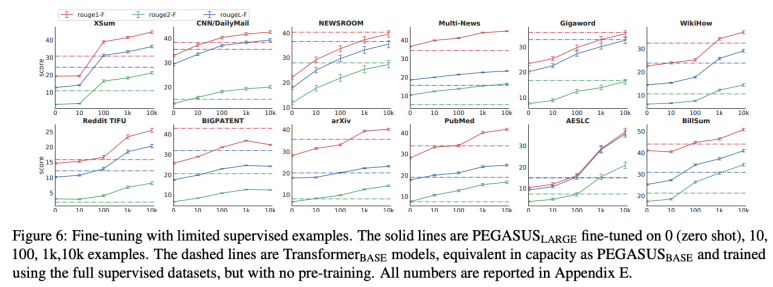
- 100개의 데이터만으로 20k~200k로 학습한 TransformerBase과 유사한 성능을 낸다.
- 1000개의 데이터로 학습했을 때 12개 데이터 셋에서 6개가 기존 SOTA보다 높은 성능을 보인다.
위의 결과로 적은 데이터로도 높은 성능을 내는 것을 볼 수 있다.
Human Evaluation
이 논문에서는 요약 모델의 결과와 사람이 직접 요약한 결과와 비교하는 실험을 진행했다. 이때 사용한 데이터 셋은 XSum, CNN/DailyMail, Reddit TIFU이다. 평가 방법은 Amazon Mechanical Turk site를 통해 1점 (Poor) ~ 5점 (Great)까지 점수를 매기도록 진행하였다.
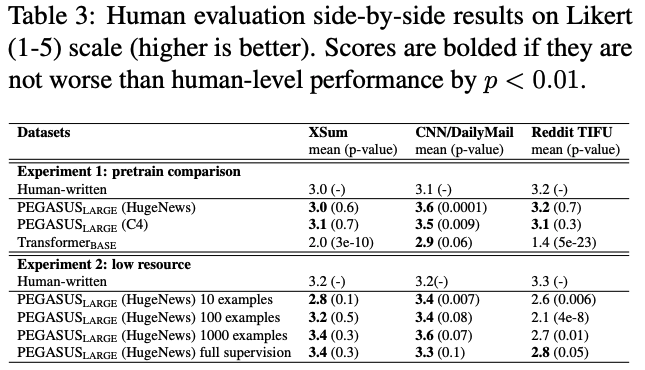
실험 1
- 실험 방법: Pegasus-large (HugeNews), Pegasus-large (C4), Transformer-base model이 생성한 요약문과 reference summaries를 비교했다.
- 실험 결과: Human evaluation에서, Pegasus-large (HugeNews)와 Pegasus-large (C4) 모두 Human-written summary (3.0 XSum, 3.1 CNNDM, 3.2 Reddit TIFU)와 비슷하거나 높은 score를 기록했다.
실험 2
- 실험 방법: Pegasus-large (HugeNews)는 10, 100, 1000 examples로 fine-tuning한 후, 각 model이 생성한 요약문과 reference summaries를 비교했다.
- 실험 결과:
- XSum, CNNDM dataset은 10 ~ 1000 examples로만 학습한 Pegasus-large model이여도 Human-written과 유사하거나 높은 score를 기록했다.
- Reddit TIFU에서는 full supervision dataset으로 학습한 model만 유사한 score를 기록하였는데, dataset의 특성이 문서 스타일이 많이 달랐기 때문에 모델의 요약본의 점수가 많이 떨어졌다.
PEGASUS-Large의 성능 향상
PEGASUS-Large의 성능을 높이기 위해 C4와 HugeNews 데이터를 함께 사전학습시켜서 실험했다.
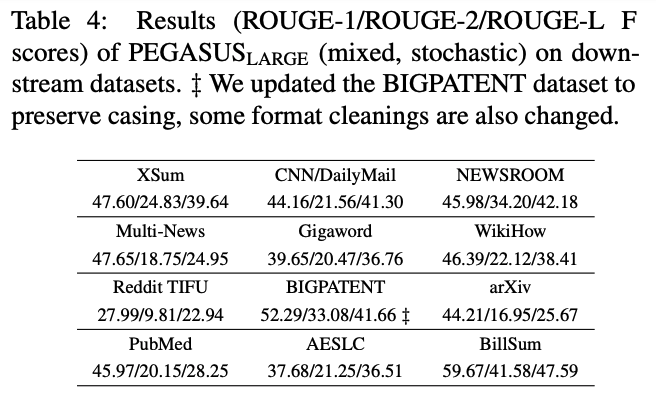
그 결과 모든 Downstream Task에서 가장 좋은 성능을 냈다.
결론
- 추상적 요약을 위한 사전학습 모델인 PEGASUS를 소개했고, 이 모델은 새로운 사전학습 기법인 GSG를 이용해 학습된다.
- 사전학습된 모델은 적은 Downstream 데이터여도 좋은 성능을 낸다.
- Human Evaluation를 통해 모델의 요약문이 사람 수준을 달성함을 보인다.